Some thoughts on Google AutoML Vision
If you read my previous posts on training a model using the TensorFlow Object Detection API to perform face mask detection, I suspect you would probably agree that the method described is not exactly a turnkey solution that would be suitable for a novice user.
So what options are available if a user just wants to train a model on their own custom dataset but wishes to do so in a simple and expedient manner whilst making use of the Cloud?
One answer is the AutoML Vision service from Google Cloud which provides a web based interface in which the user can train image classification or object detect models easily using the Google Cloud Platform (GCP) infrastructure. A beginners guide to the service can be found here.
If you have used GCP before then you eligible for $300 free credit in additional to several hours of AutoML vision node time as well.
You will still have to gather a suitable dataset that has been properly assessed, cleansed, validated and transformed yourself, although services such as Sagemaker Groundtruth or AI Platform Data Labeling Service can assist with that.
I will assume you are familiar with the basics of using GCP, if not, several excellent guides are easily accessible online.
One thing to be aware of it that the CSV format expected by AutoML Vision is different that what TensorFlow uses.
A quick search on GitHub however revealed this tool to assist you with converting your PASCAL Voc XML annotations into the required CSV format.
With the dataset is uploaded, the interface will inform you if it has found any errors with the annotations. You can manually inspect the bounding boxes and new ones if you wish however this is not really practical if you are working with large datasets.
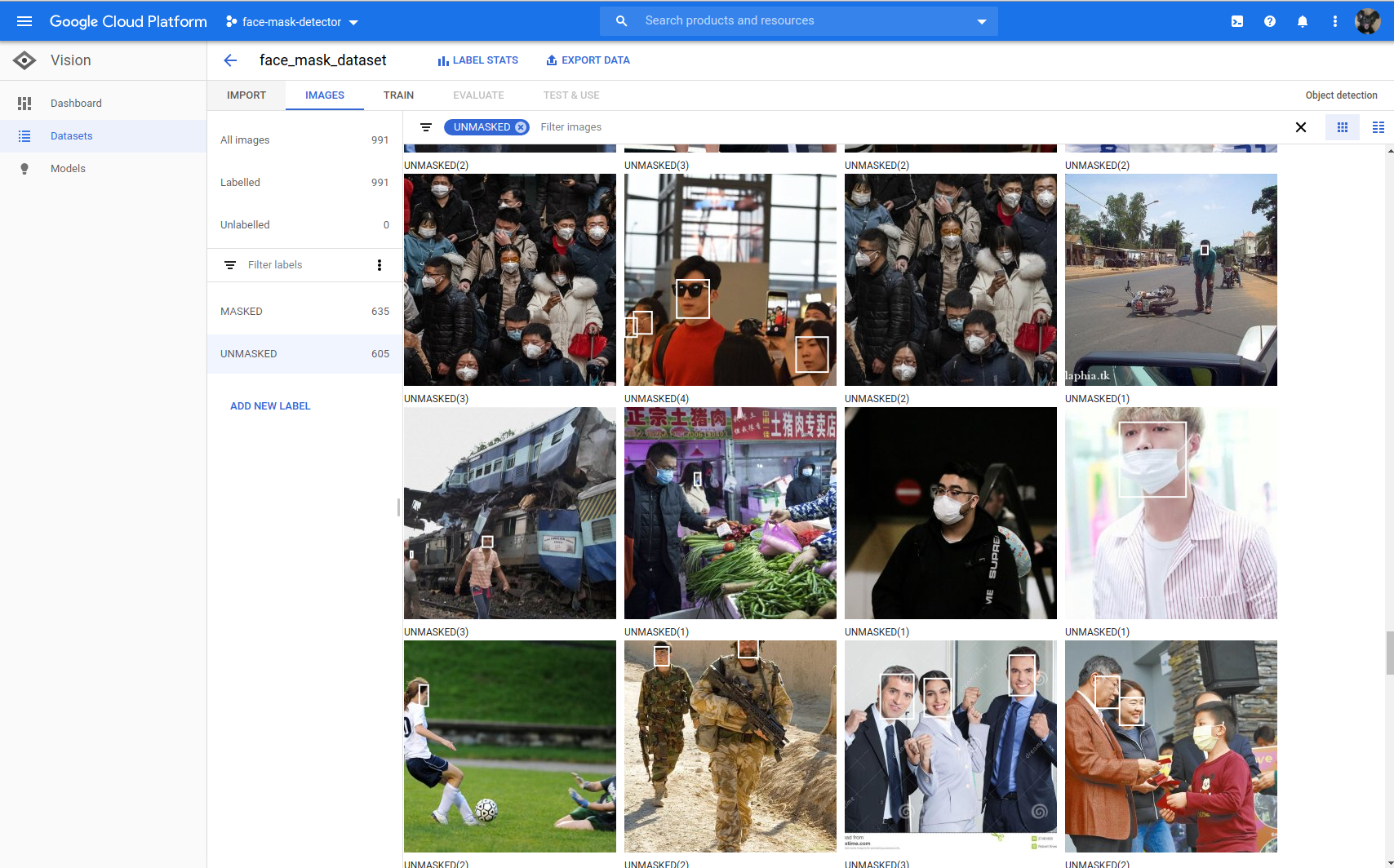
Once you are ready, its time to start the training job however in contrast to the manual training method, there are precious few options available for fine tuning the training process.
In abstracting away the complexity, a lot of the power and flexibility is also taken away at the same time.
For example you aren’t able to choose a pre-trained model on which to base your training. This would be useful if you knew of an existing pre-trained model that would be best suited for your dataset.
Once you have started the training job, it will go away and spun up the necessary resources in the background. You dont have to worry about scaling the servers in any way.
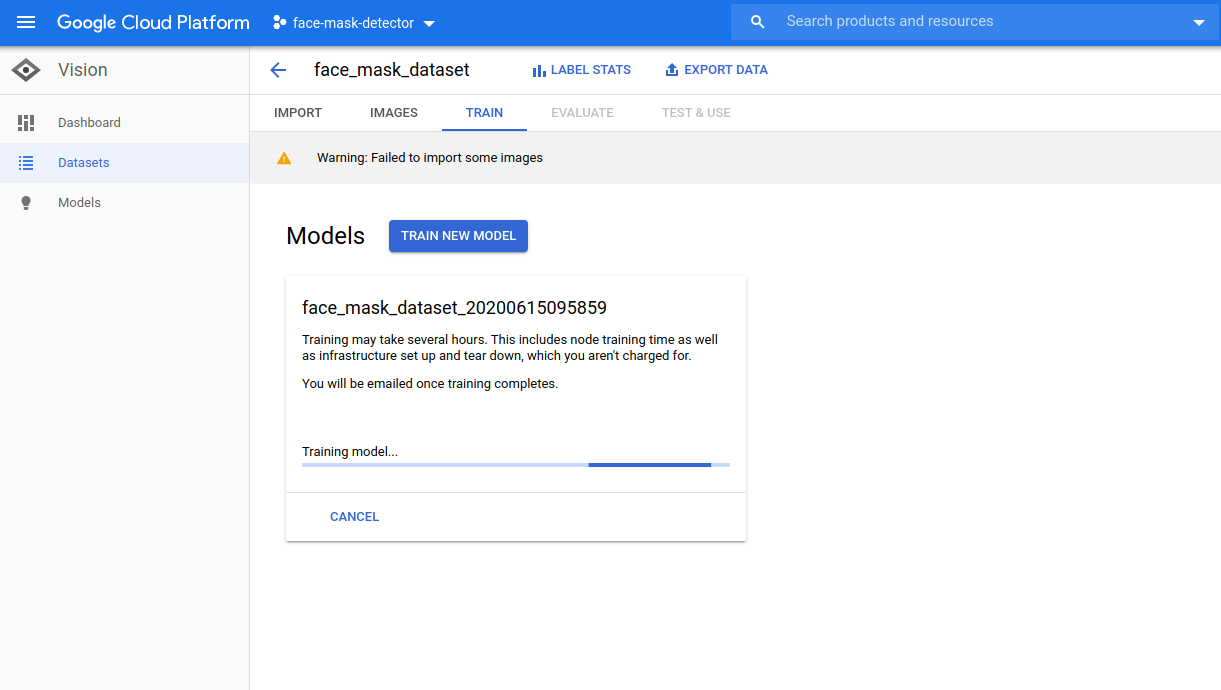
When the training job is complete, you can then view how well your model performs. In my case, whilst the precision was quite high, the recall was really poor.
If I was training this model myself then I would have been able to see that it was not going well and end the training job early so that I could make some adjustments. But in this case, I have no visibility of that and I have to wait until it is complete.
I could see the whole process getting quite expensive if I had to wait for a training job to complete, make a change and run it all over again.
In this job was intended for a production environment then obviously it would not be good enough but I was already aware that my training dataset was not ideal and you can see it was significantly imbalanced with almost double the instances of MASKED vs UNMASKED images.
I wanted to make use of the model on my Coral USB Edge TPU so I chose the TF Lite option.

With the model downloaded, I then proceeded to try it out.
TF Lite models are optimised for use on ARM CPUs so I could understand if it didnt perform great on my x86 device. My Raspeberry Pi, whilst ARM based if not suited for inference. Which leaves the Edge TPU which also displayed poor performance despite being me choosing that option in the model export.
I suspected that the model was not running all of its operations on the TPU thus slowing it down so I ran the Edge TPU compliler script on my local machine to see what was going on.
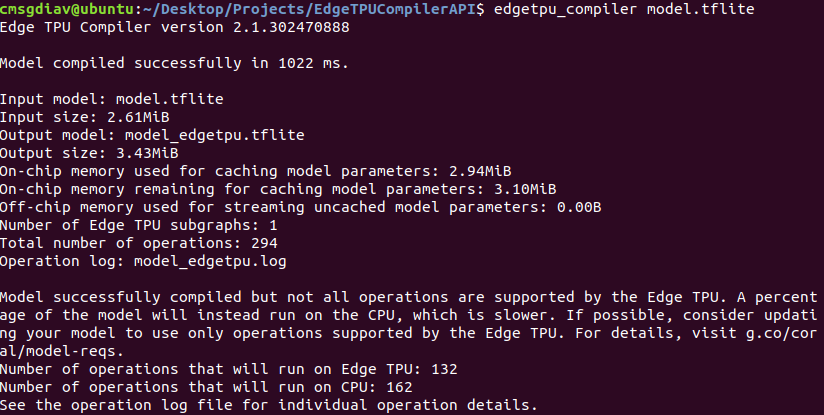
And as expected, over half the operations were running on the CPU even after the script tried to convert it.
So in summary, what is the verdict? Well, it didnt work well for me in my little experiment but for other use cases that don’t involve an Edge TPU the results might be different.
It doesnt take away the need for a quality dataset and it still requires someone with at least a basic understanding of ML concepts to be able to run through the training.
I would suggest that for all but the most basic of training jobs, it is probably more beneficial to run it yourself on a service such as Amazon Sagemaker or Google AI Platform instead.
